터빈 진동 이상 원인을 분석할 때 PI System의 한계를 체감한 적이 있습니다. 특정 시간대의 1초 단위 트렌드 데이터를 확인해야 했는데, PI Vision으로는 데이터 로딩이 느려 원인 추적이 지연됐습니다. dataPARC(PARCview)로 전환해서 급수펌프 전류, 밸브 개도, 베어링 온도를 한 화면에 겹쳐놓자, 진동 스파이크 직전에 급수 유량 제어밸브가 헌팅(Hunting)했다는 사실이 3분 만에 드러났습니다. 수십만 개의 센서에서 쏟아지는 데이터에서 원하는 신호를 얼마나 빨리 찾아내느냐가 곧 기술력인 셈이죠.
발전소 중앙제어실(MCR)의 수많은 모니터 중 엔지니어가 가장 많이 들여다보는 화면은 DCS 운전 화면이 아니라 ‘트렌드(Trend)’입니다. 전력 산업 데이터 생태계의 표준이자 핵심인 PI System과 dataPARC의 공생 관계를 실무적 관점에서 분석해 보겠습니다.
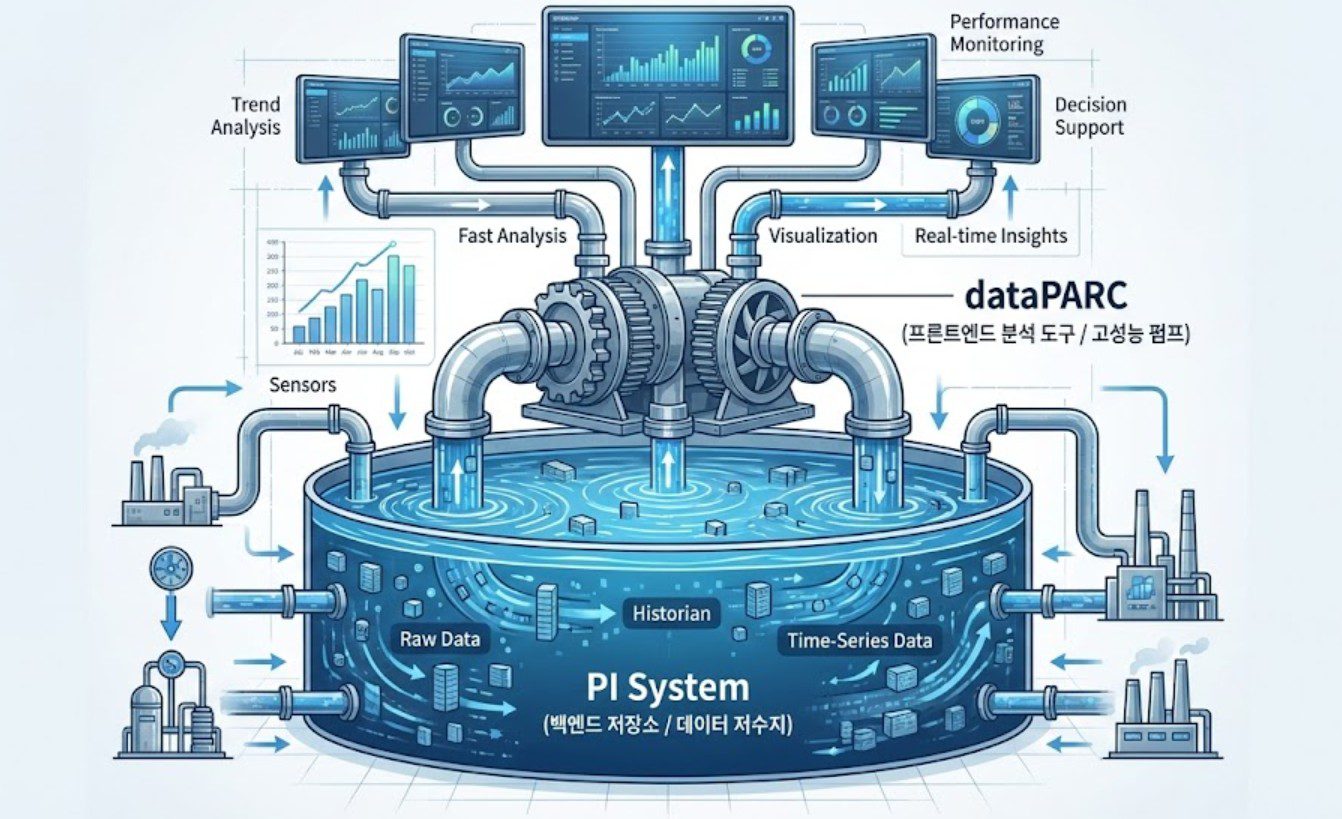
▲ 데이터의 ‘저수지’ 역할을 하는 PI System과 ‘고성능 펌프’ 역할을 하는 dataPARC
데이터의 거대한 저수지: PI System (OSIsoft/AVEVA)
PI System은 전 세계 발전소 및 공정 산업의 표준이 된 실시간 시계열 데이터베이스(Real-time Historian)입니다. 현장에서 PI를 신뢰하는 이유는 단순합니다. 바로 타협하지 않는 ‘데이터 무결성’과 ‘안정성’ 때문이죠.
- 초고속 수집: 수만 개의 센서에서 발생하는 데이터를 Swinging Door라는 독자적인 압축 알고리즘을 통해 용량은 줄이되, 중요한 변화점(Slope)은 정밀하게 저장합니다.
- 단일 진실 공급원 (Single Source of Truth): 공장의 모든 운전 이력은 PI 서버로 귀결됩니다. 강력한 이중화(HA) 구성을 통해 서버 한 대가 죽어도 데이터 유실을 허용하지 않습니다.
- 인터페이스 표준: CCS나 제어 설비가 지멘스(Siemens)든 GE든 상관없이, OPC, Modbus 등 모든 산업용 프로토콜을 지원하여 데이터를 수집합니다.
압도적인 속도의 시각화: dataPARC (Capstone)
PI System에도 ‘PI Vision’ 같은 자체 뷰어가 존재합니다. 하지만 국내외 많은 현장 엔지니어들이 dataPARC(제품명: PARCview)를 고집하는 이유는 명확합니다. 사고 분석 시 수년 치 데이터를 불러와도 버퍼링이 없는 “압도적인 속도” 때문이죠.
- 직관적인 UI: 드래그 앤 드롭으로 다수의 트렌드를 겹쳐 비교 분석하거나, 엑셀로 데이터를 추출하는 과정이 매우 직관적입니다.
- 데이터 통합: PI 데이터뿐 아니라, 실험실 데이터(LIMS), SQL, 환경 데이터(TMS) 등 이종 데이터를 한 화면에 매시업(Mashup) 할 수 있습니다.
- 가상 태그 (Calc Tag): 서버 설정을 건드리지 않고도 사용자 PC에서 복잡한 수식을 적용한 가상 태그를 생성할 수 있습니다. 이는 발전소 성능시험이나 효율 계산 시 매우 강력한 무기가 됩니다.
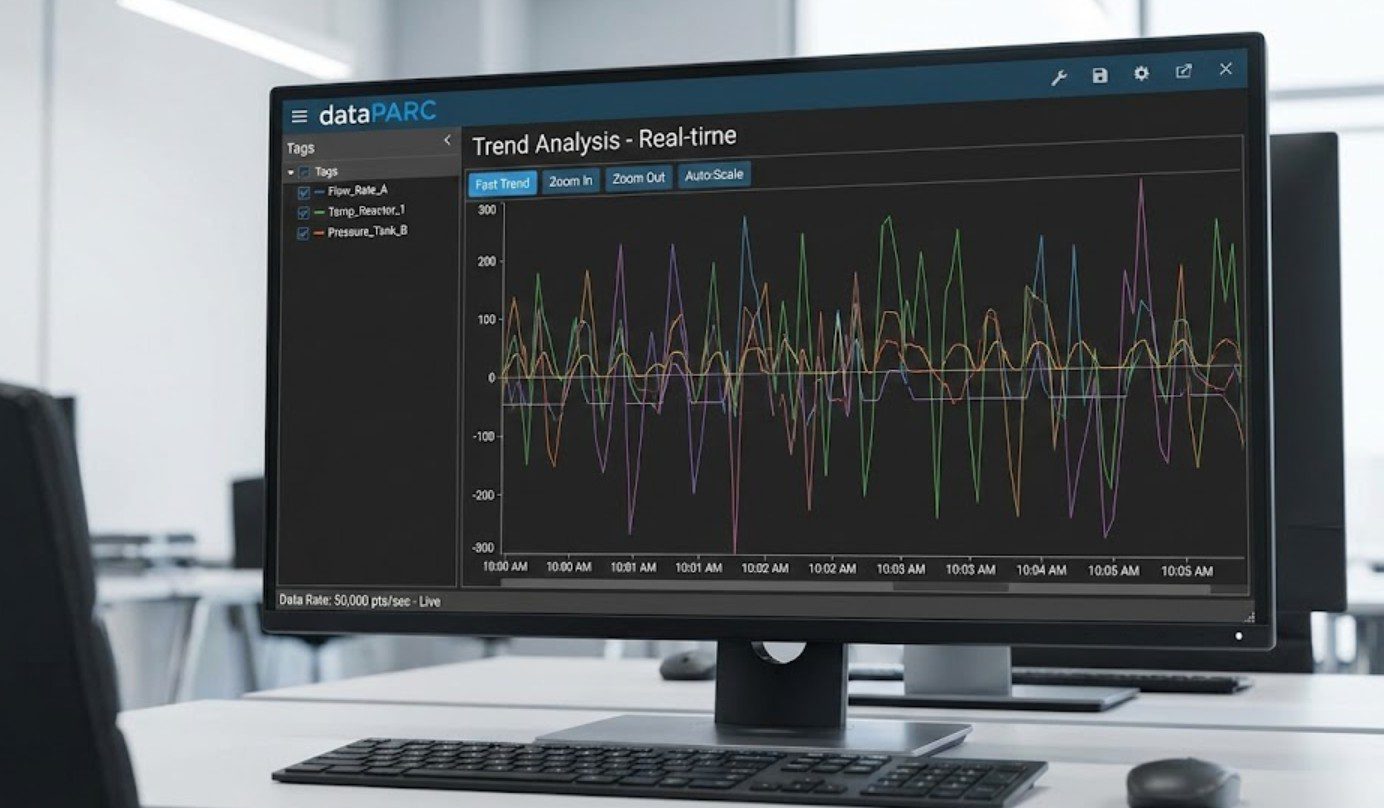
▲ 수년 치 데이터를 순식간에 로딩하여 분석할 수 있는 PARCview 인터페이스
경쟁인가 공생인가? PI System vs dataPARC
사실 dataPARC도 자체 Historian 기능을 보유하고 있어 단독 사용이 가능합니다. 하지만 국내 대형 발전소들은 이미 PI가 인프라로 구축된 경우가 많아, [PI = 백엔드 저장소], [dataPARC = 프론트엔드 분석기]로 역할을 분담하여 사용하는 것이 일종의 표준으로 자리 잡았습니다.
| 구분 | PI System (AVEVA) | dataPARC (Capstone) |
|---|---|---|
| 핵심 정체성 | Data Historian (데이터를 안전하게 모으고 저장함) | Visualization Tool (데이터를 빠르고 효율적으로 보여줌) |
| 강점 | 글로벌 표준, 압도적인 안정성, 방대한 연결성 | 초고속 조회 속도, 사용자 친화적 UI, 분석 편의성 |
| 단점 | 자체 뷰어(Vision)가 상대적으로 무거움, 고가의 라이선스 | 단독 구축 시 PI 대비 데이터 소스 확보의 범용성이 적을 수 있음 |
현장 엔지니어의 하루: 이럴 때 이걸 씁니다
상황 1: 본사 보고용 월간 운영 실적을 뽑아야 한다. PI System의 PI DataLink를 씁니다. 엑셀(Excel)과의 연동성은 PI가 타의 추종을 불허합니다. 정해진 양식에 한 달 치 데이터를 자동으로 채워 넣는 반복 업무에는 PI DataLink가 최적이죠.
상황 2: 어제 새벽 터빈 진동이 튀었는데 원인을 찾아라. dataPARC(PARCview)를 씁니다. 1초 단위 데이터(Trend)를 자유자재로 줌인/줌아웃하며, 해당 시간대에 급수펌프 전류가 흔들렸는지, 밸브 개도에 헌팅이 있었는지 인과관계를 따지기에는 dataPARC의 속도와 UI가 필수적입니다.
발전소 밖의 세상: 정유, 제약, 그리고 반도체까지
이 두 시스템은 발전소만의 전유물이 아닙니다. 시계열 데이터가 쏟아지는 모든 연속 공정(Continuous Process) 산업에서 핵심적인 역할을 수행합니다.
- 제지 및 펄프 (Pulp & Paper): dataPARC가 탄생한 본진입니다. 분당 수백 미터 속도로 생산되는 종이의 품질 데이터를 롤(Roll) 단위로 정밀 추적하여, 파단(Break) 위치를 찾아내는 데 특화되어 있습니다.
- 정유 및 석유화학 (Oil & Gas): PI System의 텃밭입니다. 고온/고압의 복잡한 화학 반응 공정을 감시하고, 공정 안전 관리(PSM) 및 에너지 효율을 최적화하는 데 필수적이죠.
- 제약 및 바이오 (Pharma): 엄격한 FDA 규제 준수를 위해 제조 이력을 기록합니다. 특히 ‘Golden Batch’ 분석 기능을 통해 최적의 배양 조건을 유지하는 데 dataPARC가 활용됩니다.
PI System 활용 현장 체크리스트
PI System과 dataPARC를 처음 접하는 엔지니어가 빠르게 실무에 적용하기 위한 핵심 포인트들입니다.
- PI DataLink 셋업: 엑셀에 PI 애드인 설치 후, 자주 쓰는 태그를 모아 월간 보고서 양식을 한번 만들어두면 매달 재활용 가능
- dataPARC 트렌드 템플릿: 주요 설비별(GT, ST, BFP 등) 기본 감시 화면을 미리 구성하여 저장, 이상 징후 발생 시 즉시 호출
- Calc Tag 활용: 효율 계산, 보정값 적용 등 반복 수식은 가상 태그로 만들어 놓으면 실시간 모니터링 가능
- 데이터 백업 확인: PI 서버 이중화(HA) 상태 주기적 점검, Archive 파일 용량 관리
- 태그 네이밍 규칙: KKS 코드와 PI 태그명의 매핑 테이블을 팀 공용 문서로 관리
결국 PI System이 아무리 데이터를 완벽하게 모으고, dataPARC가 아무리 빠르게 보여준다 해도, 이를 해석하는 것은 엔지니어의 몫입니다. 도구는 수단일 뿐, 중요한 것은 데이터 속에 숨겨진 ‘설비의 목소리’를 듣는 능력이죠. AVEVA의 PI System 공식 페이지에서 최신 기능과 업데이트를 확인할 수 있습니다. 앞으로의 현장은 단순히 데이터를 ‘보는(Monitoring)’ 수준을 넘어, AI가 패턴을 분석해 고장을 미리 알리는 ‘예지 보전’ 단계로 진화하고 있습니다.