발전소에서 멀쩡히 돌던 설비가 갑자기 멈추는 이유는 뭘까요? 고장 신호를 미리 읽지 못했기 때문입니다. 그 빈틈을 메우는 기술이 발전소 예측정비죠. 설비가 보내는 미세한 이상 징후를 데이터로 잡아, 고장이 터지기 전에 손을 쓰자는 발상입니다.
제 분야인 발전에서 일하다 보면, 가장 무서운 게 예고 없는 정지입니다. 한밤중에 발전기 한 기가 갑자기 서면, 그 빈자리를 다른 발전기가 메워야 하고 전력 수급 전체가 흔들리거든요. 그래서 요즘 발전공기업마다 AI를 붙인 예측정비를 앞다투어 도입하고 있습니다. 비용을 아끼려는 것도 있지만, 진짜 목적은 따로 있죠. 이 글에서는 예측정비가 정확히 무엇인지, 어떤 원리로 고장을 미리 아는지, 그리고 국내 발전소들이 어디까지 왔는지를 차근차근 풀어보겠습니다.
· 사후정비(BM): 고장 난 뒤 수리 — 가장 단순하지만 대형 정지 위험
· 예방정비(TBM): 달력 기준 정기점검 — 멀쩡한 부품까지 교체하는 과잉 정비 발생
· 예측정비(PdM/PHM): 설비 상태 데이터가 이상 신호를 보낼 때만 정비 — 비용·정지 최소화
· 핵심 조건: 양질의 센서 데이터 + AI 모델. 둘 중 하나만 빠져도 성립하지 않음
발전소 예측정비란 무엇인가 — 고장 신호를 미리 읽는 기술
먼저 용어부터 정리하죠. 예측정비(PdM, Predictive Maintenance)는 설비 상태 데이터를 보고 고장 나기 전에 미리 정비하는 방식입니다. 여기에 진단과 수명 예측을 통합한 기술 체계를 PHM(Prognostics and Health Management, 고장 예지 및 건전성 관리)이라고 부르죠. 발전 현장에서는 둘을 거의 같은 의미로 씁니다. 이름은 거창하지만 핵심은 한 줄입니다. 달력이 아니라 설비 상태를 보고 정비 시점을 정한다는 것이죠.
그럼 왜 하필 발전소에서 이 기술이 중요할까요. 발전기는 24시간, 1년 내내 돌아야 하는 설비입니다. 그런데 고장으로 갑자기 발전기를 세우는 비계획정지(Forced Outage)가 한 번 나면, 단순히 그 발전기만 멈추는 게 아니죠. 전력 공급의 안정성 자체가 흔들립니다. 우리나라는 전력망이 이웃 나라와 연결돼 있지 않아, 한 기가 빠지면 그 부담을 국내 다른 발전기들이 고스란히 떠안아야 하거든요. 발전소 예측정비가 단순한 비용 절감 도구가 아닌 이유가 여기 있습니다.
예측정비의 핵심은 ‘상태’를 본다는 것
기존 정비는 시간을 기준으로 삼았습니다. “3개월마다 점검”, “8,000시간 운전하면 부품 교체” 같은 식이죠. 안전하긴 합니다. 그런데 아직 멀쩡한 부품을 주기가 됐다는 이유로 갈아 끼우는 낭비가 생기고, 반대로 주기 사이에 갑자기 망가지는 부품은 못 잡습니다. 예측정비는 이 시간이라는 기준을 상태라는 기준으로 바꿉니다. 설비가 지금 어떤 상태인지를 데이터로 실시간 들여다보고, 정말 필요한 순간에만 정비하는 거죠.
사후정비·예방정비·발전소 예측정비, 무엇이 다른가
정비 방식은 크게 세 단계로 진화해 왔습니다. 가장 오래된 방식이 사후정비(BM, Break-down Maintenance)입니다. 고장이 난 뒤에 고치는, 말 그대로 가장 단순한 방식이죠. 문제는 고장 시점을 고를 수 없다는 겁니다. 한여름 전력 피크에 발전기가 서버리면 그 피해는 막대하거든요.
그래서 등장한 게 예방정비(TBM, Time-Based Maintenance)입니다. 정해진 주기에 맞춰 미리 점검하고 부품을 교체하는, 우리에게 익숙한 정기점검이죠. 사후정비보다 훨씬 안정적입니다. 하지만 앞서 말한 과잉 정비 문제가 따라옵니다. 그리고 그 다음 단계가 바로 발전소 예측정비, 즉 예측정비(PdM/PHM)입니다. 세 방식의 차이를 표로 정리하면 이렇습니다.
| 구분 | 사후정비(BM) | 예방정비(TBM) | 예측정비(PdM/PHM) |
|---|---|---|---|
| 정비 시점 | 고장 난 뒤 | 정해진 주기(시간·횟수) | 상태 데이터가 이상 신호를 보낼 때 |
| 특징 | 가장 단순, 대형 정지 위험 | 안정적이나 과잉 정비 발생 | 필요할 때만 정비 → 비용·정지 최소화 |
| 핵심 과제 | 고장 자체를 못 피함 | 적정 주기 설정의 어려움 | 양질의 센서 데이터 + AI 모델 구축 |
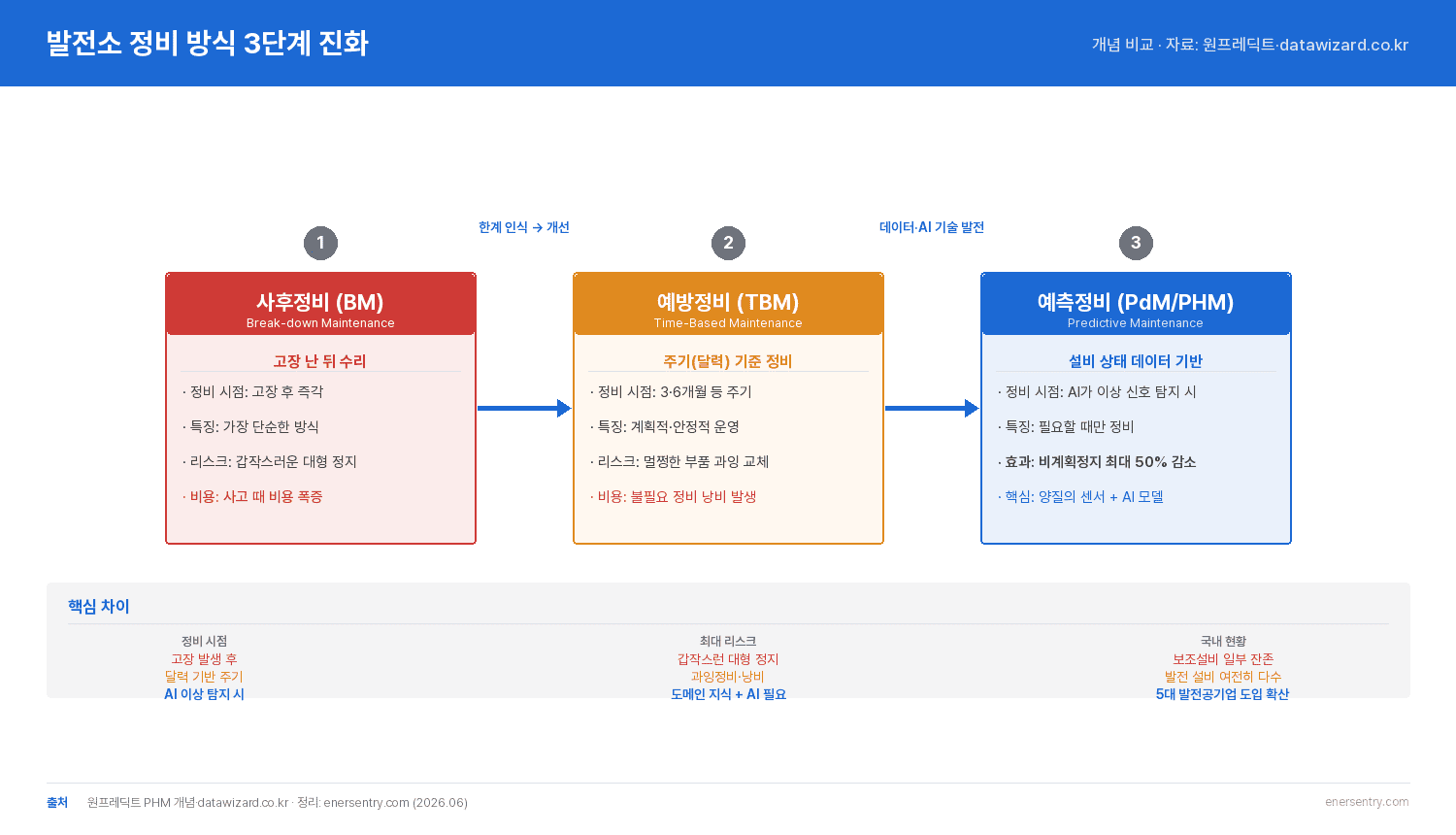
▲ 사후정비(고장 후) → 예방정비(주기 기준) → 예측정비(상태 기준, AI)로 이어지는 3단계 진화.
달력 기반 예방정비와 상태 기반 발전소 예측정비는 다르다
여기서 가장 흔한 오해를 짚고 가죠. 예방정비와 예측정비를 같은 말로 쓰는 분이 많습니다. 둘 다 “미리 한다”는 점은 같으니까요. 그런데 결정적으로 다릅니다. 예방정비는 달력 기반입니다. 3개월이 지났으니까, 운전 시간이 찼으니까 점검하는 거죠. 반면 발전소 예측정비는 상태 기반입니다. 달력이 며칠을 가리키든 상관없이, 설비가 이상 신호를 보낼 때 움직입니다. 교과서에선 PM(예방정비)과 PdM(예측정비)을 칼같이 나누지만, 실무에선 둘을 뭉뚱그려 쓰는 경우가 많아 더 헷갈리는 겁니다.
발전소 예측정비는 어떻게 고장을 미리 아는가
그렇다면 AI는 대체 무슨 수로 고장을 미리 알까요. 마법은 아닙니다. 예측정비는 다섯 단계의 데이터 흐름을 거칩니다. 센서로 신호를 모으고, 그 신호를 다듬고, 이상한 패턴을 찾아내고, 원인을 짚고, 마지막으로 얼마나 더 버틸지를 계산하는 순서죠.
- 데이터 취득(Sensing) — 온도·진동·압력·전류 센서를 설비에 붙여 초당 수천~수만 개 신호 수집
- 전처리·특징 추출(Feature Extraction) — 잡음을 제거하고 FFT·STFT로 주파수를 변환해 핵심 파라미터만 압축
- 이상탐지(Anomaly Detection) — 정상 운전 패턴과의 편차를 딥러닝(CNN·LSTM 등)이 확률로 표시
- 고장 진단(Diagnostics) — 어느 부품에서 어떤 이상이 시작됐는지 원인을 식별
- 잔여수명 예측(RUL) — “앞으로 몇 달 뒤 교체가 필요하다”는 예측을 정비 계획에 반영
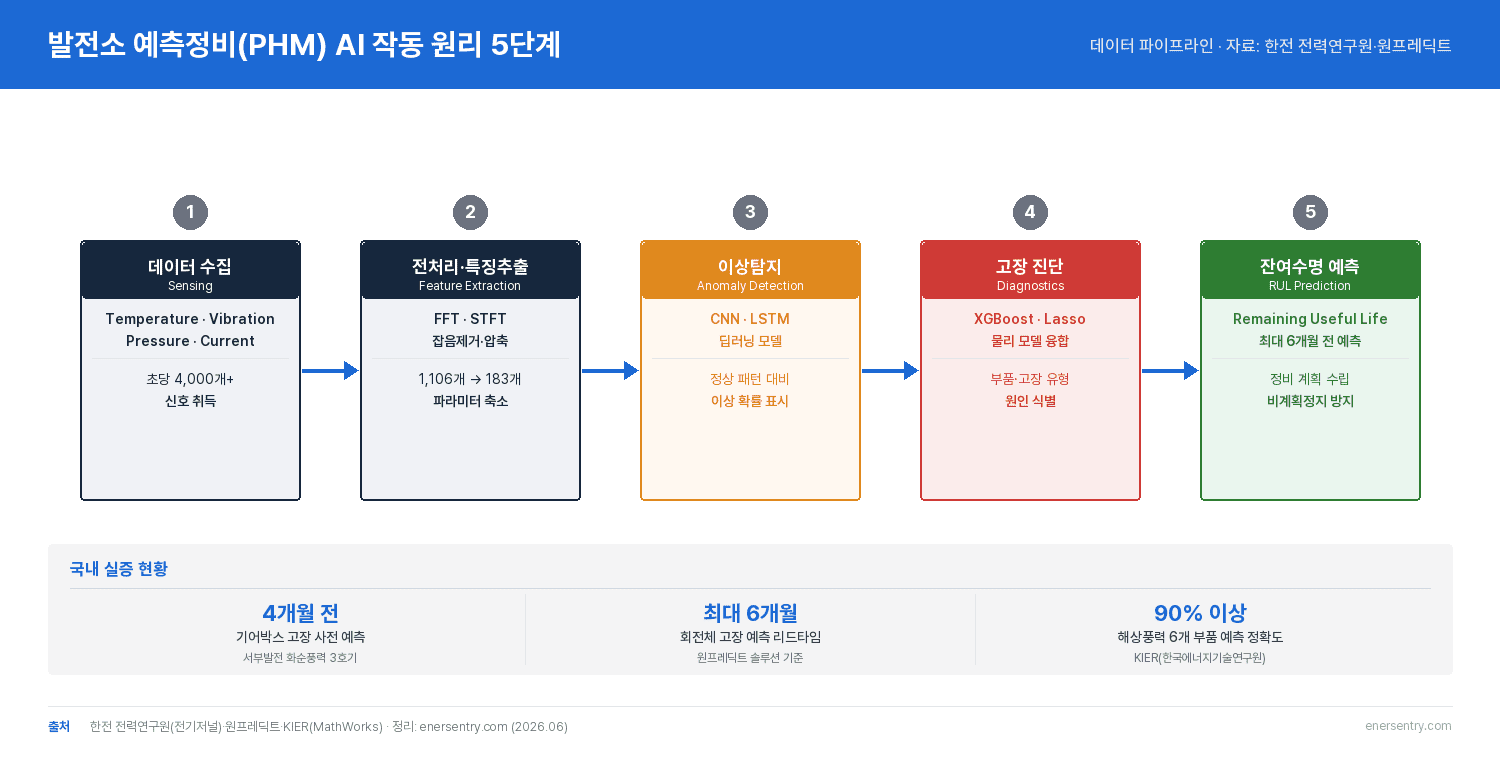
▲ 발전소 예측정비 5단계 — 센서 데이터 수집부터 잔여수명(RUL) 예측·정비 계획까지의 흐름.
출발점은 초당 수천 개의 센서 데이터
모든 건 데이터에서 시작합니다. 한전 전력연구원이 만든 가스터빈 진단 모델 DeepThink-Gas Turbine은 초당 4,000개 이상의 센서 데이터를 받아들입니다. 사람이 일일이 들여다볼 수 있는 양이 아니죠. 그래서 머신러닝(XGBoost, Lasso)으로 1,106개나 되던 센서 파라미터를 183개로 추려냈습니다. 핵심만 남기고 잡음을 걷어낸 거죠. 이렇게 발전소가 쏟아내는 방대한 운전 데이터를 어떻게 모으고 활용하는지는 발전소의 두뇌, PI System과 dataPARC에서 더 자세히 다뤘습니다.
이상탐지에서 잔여수명 예측까지
데이터가 정리되면 AI가 정상 패턴과 비교합니다. 평소와 다른 진동, 평소와 다른 온도 상승이 보이면 이상탐지가 작동하죠. 여기서 끝이 아닙니다. 어느 부품의 어떤 결함인지 진단하고, 마지막으로 잔여수명(RUL, Remaining Useful Life)을 계산합니다. 설비가 고장 나기까지 남은 시간을 숫자로 내놓는 거죠. 발전소 예측정비의 진짜 가치는 이 마지막 단계에 있습니다. “이상이 있다”가 아니라 “앞으로 4개월 정도 더 버틸 수 있으니 다음 정비 때 같이 교체하자”는 식의 구체적인 의사결정을 가능하게 하니까요.
발전소 예측정비가 특히 집중하는 설비
발전소 안의 모든 설비에 예측정비를 똑같이 거는 건 아닙니다. 효과가 큰 곳, 즉 고장 났을 때 손실이 크고 정비비가 비싼 회전체에 먼저 집중하죠. 대표 선수가 가스터빈입니다. 진동·온도·압력을 복합으로 분석하는데, 국내 가스터빈은 사실상 전량 수입이라 부품 수급이 어렵고 정비비가 막대합니다. 국내 발전공기업이 25년간 가스터빈 유지보수에 쓴 누적 비용이 약 4.2조 원에 이른다는 집계도 있거든요. 비싼 설비일수록 예측정비의 효과가 극대화되는 셈이죠.
풍력발전기도 핵심 대상입니다. 기어박스·베어링·발전기를 집중 모니터링하는데, 특히 해상풍력은 배를 타고 나가야 접근할 수 있어 사람이 수시로 들여다보기 어렵습니다. 그러니 멀리서 상태를 읽는 예측정비의 가치가 더 클 수밖에요. 펌프와 압축기 같은 보조설비는 진동 신호로 베어링 마모나 공동현상(cavitation)을 조기에 잡아냅니다. 보일러 열교환기는 오염(fouling) 진행을 온도·압력 차로 추적하죠.
진동 신호가 회전체의 건강을 말해준다
회전체에서 가장 정직한 신호가 진동입니다. 베어링이 마모되거나 축이 틀어지기 시작하면, 사람 귀로는 못 듣는 미세한 진동 변화가 먼저 나타나거든요. 현장에서 보면, 진동 추세가 슬금슬금 올라가는 설비는 거의 예외 없이 어딘가에 문제가 자라고 있습니다. 이 진동을 어떻게 읽고 대응하는지는 급수펌프(BFP) 진동 상승 시 엔지니어의 체크리스트에 정리해 뒀습니다. 사람이 못 듣는 신호를 기계가 먼저 듣고, 그 미세한 변화를 추세로 쌓아 경고를 띄우는 셈이죠.
발전소 예측정비, 국내 발전공기업은 어디까지 왔나
이론은 그렇다 치고, 실제로 효과가 있을까요. 가장 또렷한 사례가 한국서부발전 화순풍력입니다. AI 예측정비 솔루션(가디원 윈드)을 적용했더니, 풍력터빈 한 기당 약 5억 2,000만 원의 경제 효과가 나왔습니다. 8기에 적용하면 연간 약 42억 원의 수익 증대로 이어진다는 계산이죠. 무엇보다 인상적인 건, 화순풍력 3호기의 기어박스 고장을 실제로 4개월 전에 사전 예측했다는 사실입니다. 4개월이면 부품을 주문하고 정비 일정을 느긋하게 짤 수 있는 시간이거든요.
다른 발전공기업도 움직이고 있습니다. 서부발전은 2024년 11월 충남 태안에 WISE 예측진단센터를 열었고, 한국동서발전은 e-PHI라는 AI 예측경보시스템을 자체 개발해 운영 중이죠. 다만 동서발전의 구체적인 성과 수치는 아직 공개되지 않아, 정량적 효과는 추정에 머무릅니다. 한국중부발전은 신보령화력 1000MW급에 산업AI 기반 예지보전을 적용했는데, “세계 최초 1000MW급 적용”이라는 수식어는 솔루션 공급사(원프레딕트)의 자사 발표라는 점은 감안해서 봐야 합니다.
숫자로 보는 효과 — 단, 글로벌 수치는 구분해서
여기서 숫자를 읽을 때 주의할 점이 있습니다. 국내 사례 수치와 글로벌 연구 수치를 섞으면 안 됩니다. 글로벌 연구 기준으로는, 예측정비를 도입하면 비계획정지가 최대 50%까지 줄고, 설비 가동률이 10~20% 향상되며, 정비비는 18~25% 절감된다는 분석이 있습니다(Deloitte Insights 보고서). 다만 이건 제조업 전반을 아우른 글로벌 수치이지, 국내 발전소에 그대로 적용되는 값은 아니죠. 국내 해상풍력에서는 한국에너지기술연구원(KIER)이 6개 주요 부품의 예측 정확도를 모두 90% 이상으로 끌어올린 사례가 보고됐고, 회전체 기준으로 최대 6개월 전 고장 예측이 가능하다는 솔루션 사례도 있습니다.
발전소 예측정비를 둘러싼 흔한 오해 3가지
발전소 예측정비를 처음 접하면 으레 빠지는 오해가 몇 가지 있습니다. 정확히 이해하려면 이 오해부터 걷어내야 하죠.
확률·데이터·확산 — 세 가지를 헷갈리지 말 것
첫째, “AI가 100% 맞힌다”는 오해입니다. 아닙니다. 한전 전력연구원조차 자사 모델을 두고 “100% 완벽한 성능이라고 말할 수는 없다”고 분명히 밝혔거든요. 고장 데이터 자체가 부족한 게 공통된 과제입니다. 정상 운전 데이터는 넘쳐나는데, 정작 고장이 난 순간의 데이터는 드무니까요. AI는 어디까지나 확률을 계산하는 도구이고, 최종 정비 의사결정은 여전히 엔지니어의 몫입니다.
둘째, “빅데이터만 모으면 된다”는 오해입니다. 데이터가 많다고 저절로 예측이 되는 게 아니죠. 설비를 이해하는 물리 기반 모델, 즉 도메인 지식과 데이터 기반 AI를 융합해야 효과가 납니다. 회전체 진단에서는 물리 모델 70~80%에 AI 20~30%를 결합하는 구조가 효과적이라는 게 현장에서 확인된 경험칙이죠. 발전 설비를 모르는 데이터 과학자만으로는 풀리지 않는 문제라는 뜻입니다.
셋째, “이미 모든 발전소가 쓰고 있다”는 오해입니다. 현실은 그렇지 않습니다. 국내 발전공기업 가운데 일부가 파일럿이나 일부 설비 상용화 단계에 있고, 전 설비로의 확대는 아직 진행 중입니다. 서부발전 WISE나 동서발전 e-PHI도 모든 기종을 커버하는지는 공개되지 않았죠. 발전소 예측정비는 빠르게 퍼지고 있는 기술이지만, “이미 끝난 일”은 아니라는 게 정확한 표현입니다.
참고로 발전 현장에 AI가 들어오면서 일하는 방식 자체가 어떻게 바뀌고 있는지는 AI 업무 자동화로 바뀐 발전 엔지니어의 하루에서 다른 각도로 풀어봤습니다.
발전소 예측정비, 결국 무엇을 봐야 하나
여기까지 보면 큰 그림이 잡힙니다. 발전소 예측정비는 고장 난 뒤 고치는 사후정비, 달력 따라 점검하는 예방정비를 지나, 설비 상태를 실시간으로 읽어 필요할 때만 정비하는 단계입니다. 센서가 쏟아내는 데이터에서 이상 징후를 찾아 잔여수명까지 계산하고, 그걸 정비 계획에 반영하죠. 발전공기업들이 이 기술에 투자하는 진짜 이유는 비용보다 “예고 없는 정지”를 막아 전력 안정성을 지키는 데 있습니다.
제 분야인 발전의 시각에서 한 가지만 덧붙이죠. 발전소 예측정비는 AI 기술 경쟁이 아니라, 결국 데이터와 도메인 지식의 싸움입니다. 좋은 센서를 제대로 붙이고, 그 신호를 발전 설비의 물리를 아는 사람이 해석할 때 비로소 예측이 맞아 들어가거든요. 그래서 이 기술을 지켜볼 때는 “어떤 AI를 썼나”보다 “어떤 데이터를, 누가, 어떻게 해석하는가”를 봐야 합니다.
· 정의: 설비 상태 데이터로 고장 전에 정비하는 방식(PdM) + 진단·수명예측을 통합한 체계(PHM)
· 진화 순서: 사후정비(고장 후) → 예방정비(주기 기준) → 예측정비(상태 기준, AI)
· 작동 5단계: 센서 데이터 → 전처리·특징 추출 → 이상탐지 → 고장 진단 → 잔여수명(RUL) 예측
· 집중 설비: 가스터빈·풍력 기어박스 등 회전체(고가·수입 부품일수록 효과 극대화)
· 국내 사례: 서부발전 화순풍력 기어박스 4개월 전 예측·기당 5.2억 원 효과, WISE 예측진단센터(2024.11)
· 주의: AI는 100%가 아님(확률 도구), 물리 모델+AI 융합 필요, 전 설비 확대는 진행 중
· 글로벌 연구 기준: 비계획정지 최대 50%↓·가동률 10~20%↑·정비비 18~25%↓(국내 특정 수치 아님)